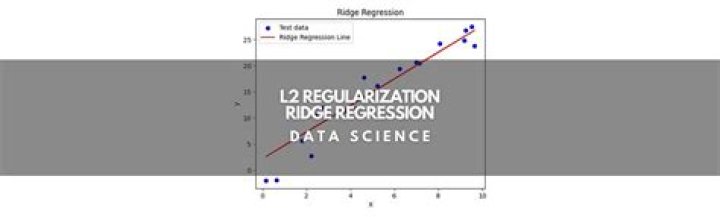
How does ridge regression deal with multicollinearity?
estimates
Estimation (or estimating) is the process of finding an estimate or approximation, which is a value that is usable for some purpose even if input data may be incomplete, uncertain, or unstable. The value is nonetheless usable because it is derived from the best information available.
› wiki › Estimation
bias
In statistics, the bias (or bias function) of an estimator is the difference between this estimator's expected value and the true value of the parameter being estimated. An estimator or decision rule with zero bias is called unbiased.
› wiki › Bias_of_an_estimator
variances
In other words, the variance of X is equal to the mean of the square of X minus the square of the mean of X.
› wiki › Variance
How do you deal with multicollinearity in regression?
How to Deal with Multicollinearity
- Remove some of the highly correlated independent variables.
- Linearly combine the independent variables, such as adding them together.
- Perform an analysis designed for highly correlated variables, such as principal components analysis or partial least squares regression.
What is ridge regression good for?
Ridge regression is the method used for the analysis of multicollinearity in multiple regression data. It is most suitable when a data set contains a higher number of predictor variables than the number of observations. The second-best scenario is when multicollinearity is experienced in a set.What is the most appropriate way to control for multicollinearity?
How to fix the Multi-Collinearity issue? The most straightforward method is to remove some variables that are highly correlated to others and leave the more significant ones in the set.Which models can handle multicollinearity?
Multicollinearity occurs when two or more independent variables(also known as predictor) are highly correlated with one another in a regression model. This means that an independent variable can be predicted from another independent variable in a regression model.Ridge regression explained: Regression robust to multicollinearity (Excel)
Why multicollinearity is a problem in regression?
Multicollinearity is a problem because it undermines the statistical significance of an independent variable. Other things being equal, the larger the standard error of a regression coefficient, the less likely it is that this coefficient will be statistically significant.How do you deal with highly correlated features?
The easiest way is to delete or eliminate one of the perfectly correlated features. Another way is to use a dimension reduction algorithm such as Principle Component Analysis (PCA).How would you remove the chances of multicollinearity?
One of the most common ways of eliminating the problem of multicollinearity is to first identify collinear independent variables and then remove all but one. It is also possible to eliminate multicollinearity by combining two or more collinear variables into a single variable.How does clustering deal with multicollinearity?
To handle multicollinearity, the idea is to perform hierarchical clustering on the spearman rank order coefficient and pick a single feature from each cluster based on a threshold. The value of the threshold can be decided by observing the dendrogram plots.When there is multicollinearity in an estimated regression equation?
Multicollinearity can affect any regression model with more than one predictor. It occurs when two or more predictor variables overlap so much in what they measure that their effects are indistinguishable. When the model tries to estimate their unique effects, it goes wonky (yes, that's a technical term).How does regularization prevent multicollinearity?
To reduce multicollinearity we can use regularization that means to keep all the features but reducing the magnitude of the coefficients of the model. This is a good solution when each predictor contributes to predict the dependent variable. The result is very similar to the result given by the Ridge Regression.Why is ridge regression better than linear regression?
Linear Regression establishes a relationship between dependent variable (Y) and one or more independent variables (X) using a best fit straight line (also known as regression line). Ridge Regression is a technique used when the data suffers from multicollinearity ( independent variables are highly correlated).Does ridge regression reduce bias?
Just like Ridge Regression Lasso regression also trades off an increase in bias with a decrease in variance.How do you know if multicollinearity is a problem?
In factor analysis, principle component analysis is used to drive the common score of multicollinearity variables. A rule of thumb to detect multicollinearity is that when the VIF is greater than 10, then there is a problem of multicollinearity.Does multicollinearity affect R Squared?
If the R-Squared for a particular variable is closer to 1 it indicates the variable can be explained by other predictor variables and having the variable as one of the predictor variables can cause the multicollinearity problem.What VIF value indicates multicollinearity?
Generally, a VIF above 4 or tolerance below 0.25 indicates that multicollinearity might exist, and further investigation is required. When VIF is higher than 10 or tolerance is lower than 0.1, there is significant multicollinearity that needs to be corrected.Does Lasso regression deal with multicollinearity?
Lasso RegressionAnother Tolerant Method for dealing with multicollinearity known as Least Absolute Shrinkage and Selection Operator (LASSO) regression, solves the same constrained optimization problem as ridge regression, but uses the L1 norm rather than the L2 norm as a measure of complexity.
Should I remove correlated variables before clustering?
It's advisable to remove variables if they are highly correlated. Irrespective of the clustering algorithm or linkage method, one thing that you generally follow is to find the distance between points.Should we remove highly correlated variables for clustering?
The short answer is no, you don't need to remove highly correlated variables from clustering for collinearity concerns. Clustering doesn't rely on linear assumptions, and so collinearity wouldn't cause issues. That doesn't mean that using a bunch of highly correlated variables is a good thing.What should you do if two of your independent variables are found to be highly correlated?
If the correlation between two of your independent variables is as high as . 918, the answer is simple.
...
- Drop one of the correlated independent variables.
- Obtain more data, if possible or treat all the data rather than subset of the data.
- Transform one of the correlated variable by :